Sutro Functions Overview (Research Preview)
Summary
Sutro Functions are task-specific classifiers or extractors that are aligned with your decision preferences and inexpensive to run. We offer a declarative, iterative interface for building these functions that abstracts away model selection, prompt engineering, and upfront data labeling.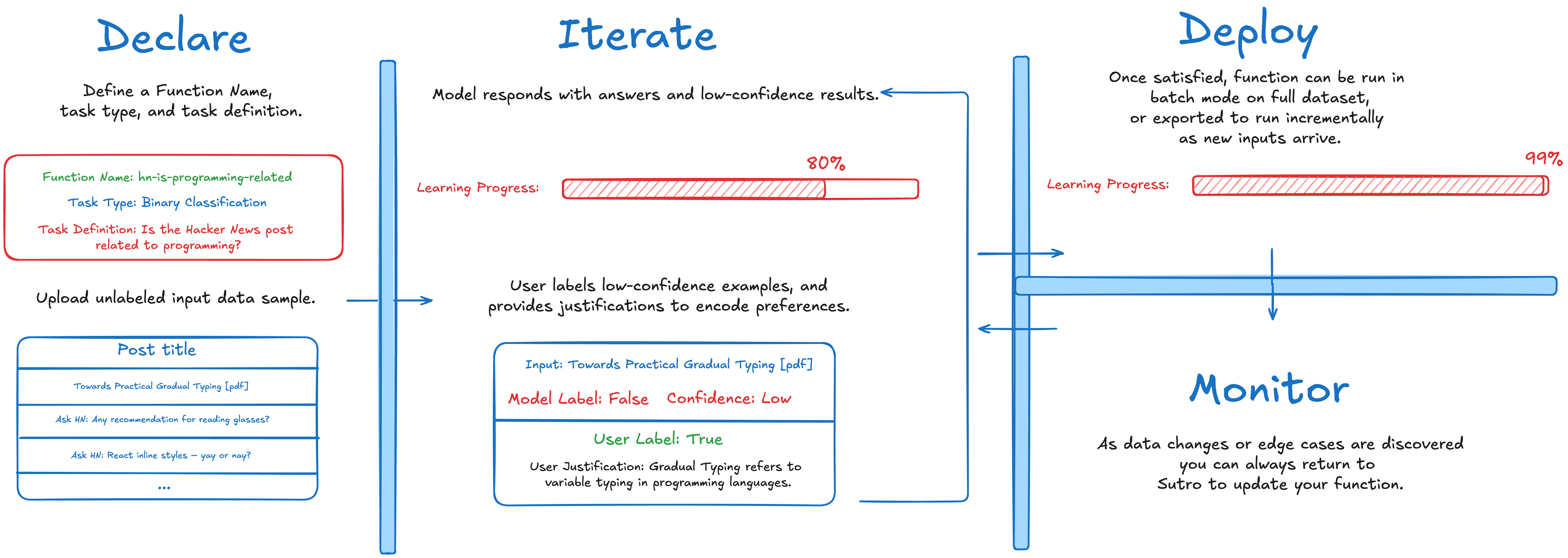
Why Sutro Functions?
When using AI to solve specific, repeated tasks it is often suboptimal to reach for large, general-purpose foundation models. Instead, it is often more practical to create a task-specific model that is:- Highly accurate and aligned with your organization’s decision preferences (more so than an out-of-the-box foundation model)
- Consistent and low-variance across inputs (often not the case with foundation models)
- As small and cheap to run as possible (especially when scaling to large datasets or many inputs over time)
How does it work?
Start by uploading an unlabeled dataset, choosing a task type (ex. binary classification), and creating a simple task definition (ex. “Determine if this is a qualified lead for my business.”). The system iteratively learns decision preferences, surfacing examples where model confidence is low as well as overall learning progress metrics. The user then labels low-confidence examples and provides justifications for the responses, encoding preferences as it iterates. The user can also view high-confidence results (along with other uploaded correlative data if desired) and optionally re-label cases where confidence is high but labels are incorrect. After a few iterations, it typically converges on a highly-aligned task representation which can then be deployed on Sutro’s efficient batch inference service or exported for external usage. Once in production, you can also use Sutro to detect anomalies or data drift, and return to Sutro Functions at any time to make updates to the function.What can I do with a Sutro Function?
We currently support text-based classification (binary, multi-class, and multi-label) and structured extraction tasks only, but plan on adding support for other analytical tasks like, matching, scoring, and more in the future - as well as expand to image and video inputs. Classification and extraction tasks cover a wide range of high-value enterprise and research problems including:- Lead scoring
- Support routing and triage systems
- Document categorization
- Address normalization
- Web-page extraction
- Fraud and scam/spam detection
- Semantic tagging for downstream analytics
- Data quality filtering
- Product catalog taxonomies
- Merchant categorization
- Model/query routers
- Churn-prediction models
- Call transcript analysis
- Invoice extraction
- Legal contract extraction
- Many, many more!
How can I get started?
Sutro Functions is currently in research preview, and we are working with a small set of motivated design partners to improve the methododology and product experience before a self-serve release. If you are interested in joining the preview or getting a demo, send a message to team@sutro.sh.FAQ
What if I already have labeled data for my task?
What if I already have labeled data for my task?
Even better! We can use those labels to pre-populate each iteration or serve as correlative references, but we still recommend providing justifications to encode preferences.
What does this yield?
What does this yield?
A small, preference-aligned AI model that can be used on larger datasets or many one-off task invocations.
How can I run a Function after it has been created?
How can I run a Function after it has been created?
On Sutro’s batch inference service, or via a self-hosted solution in your environment.
Is this a new methodology, or just a new interface?
Is this a new methodology, or just a new interface?
Both! We are happy to share more technical details about the under-the-hood approach, but intend for this guide to be more outcomes-focused.
How much will they cost?
How much will they cost?
Significantly less expensive to run than large foundation models. However, true ROI should be assessed via relative accuracy gains and overall task value.
How well does it work?
How well does it work?
Sutro Functions is still in active development, but we have seen extremely promising results. Generally speaking if a task is well-scoped from the start and the sample data contains a realistic distribution of label outcomes, it will succeed in encoding user preferences to a high-degree. We plan to release benchmarks showing relative performance gains in the near future.
How long does it take to create a new function?
How long does it take to create a new function?
Our aim is to make it significantly faster than prompt engineering, with superior results.
How complicated can tasks be?
How complicated can tasks be?
Generally speaking, you should reduce a task down to it’s simplest form for best results. For example, it may be helpful to break a larger, more complex problem like a lead-scoring model into several binary classifiers to more accurately solve that problem.
Why not just use a bigger, smarter model instead of Sutro Functions?
Why not just use a bigger, smarter model instead of Sutro Functions?
Generally speaking, foundation models do not improve on subjective tasks as they get larger or more generally capable. Sutro Functions aims to improve accuracy when preference-encoding or domain expertise is required. You can think of it like a last-mile solution for AI.
How is this different than traditional ML classifiers?
How is this different than traditional ML classifiers?
Sutro Functions are suited for unstructured input data (text, images, etc. - not numerical), and alleviate the need for upfront data labeling.
Can I update a Sutro Function after it has been deployed?
Can I update a Sutro Function after it has been deployed?
Yes, and we plan to offer the ability to mark incorrect production instantiations for further refinement over time.